
前段时间完成了一个Excel导出导入的功能,期间碰到很多问题,最终一一解决了。其中涉及到了java的反射,自定义注解的使用,POI API的使用,Excel下拉列表如何通过代码设置,文件上传等问题。也许有其他人也会碰到这样的问题,将源码分享出来,希望可以帮到他们。
源码包括 :
jar包,也可以使用pom方式导入,本系统使用的3.8版本
excel工具类,反射工具类,字典工具类,注解类等
文件上传工具类
示例的控制层、服务层、实体类
Html示例页面以及上传组件
模板页面
接下来重点解析一下源码
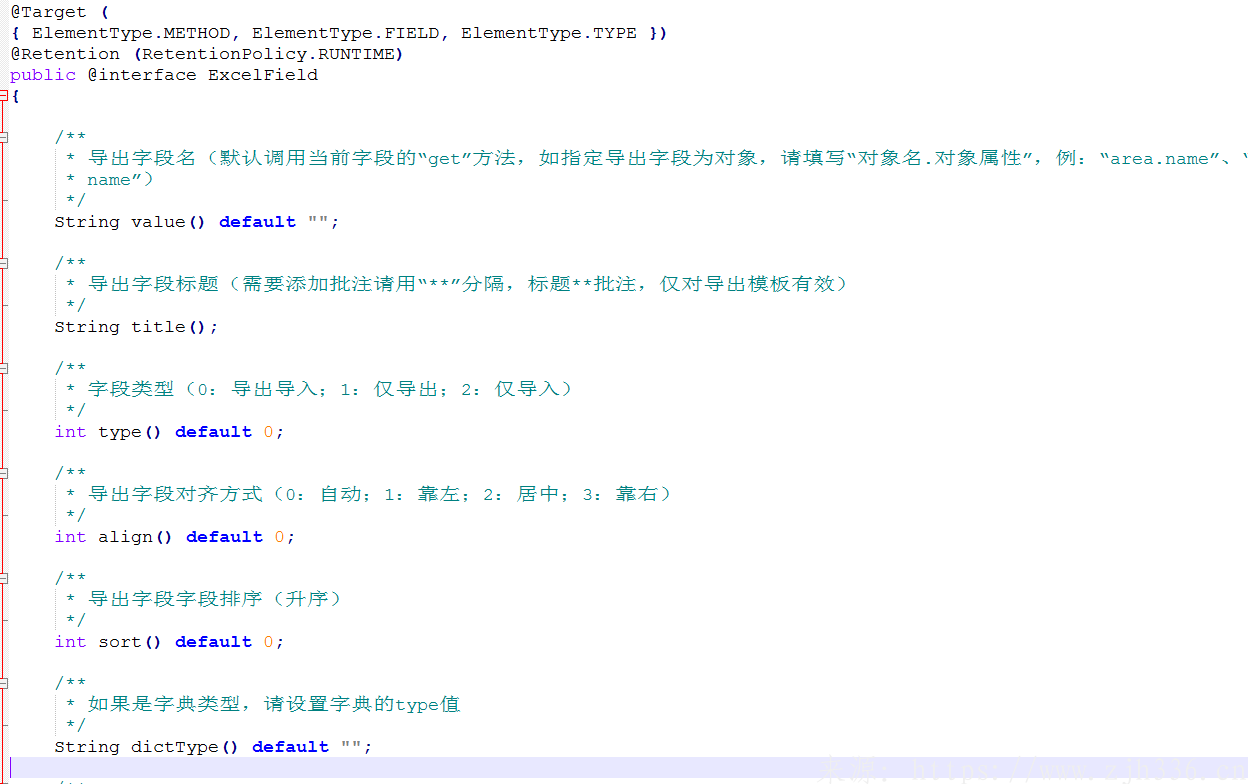
一、注解类
最常用的是title sort dictType ,分别是标题,排序,字典。标题就是到处excel的标题名称,sort就是excel横向排第几个,dictType就是字典的key值,用于导出的值域转换显示,以及导出模板的下拉框值域来源。
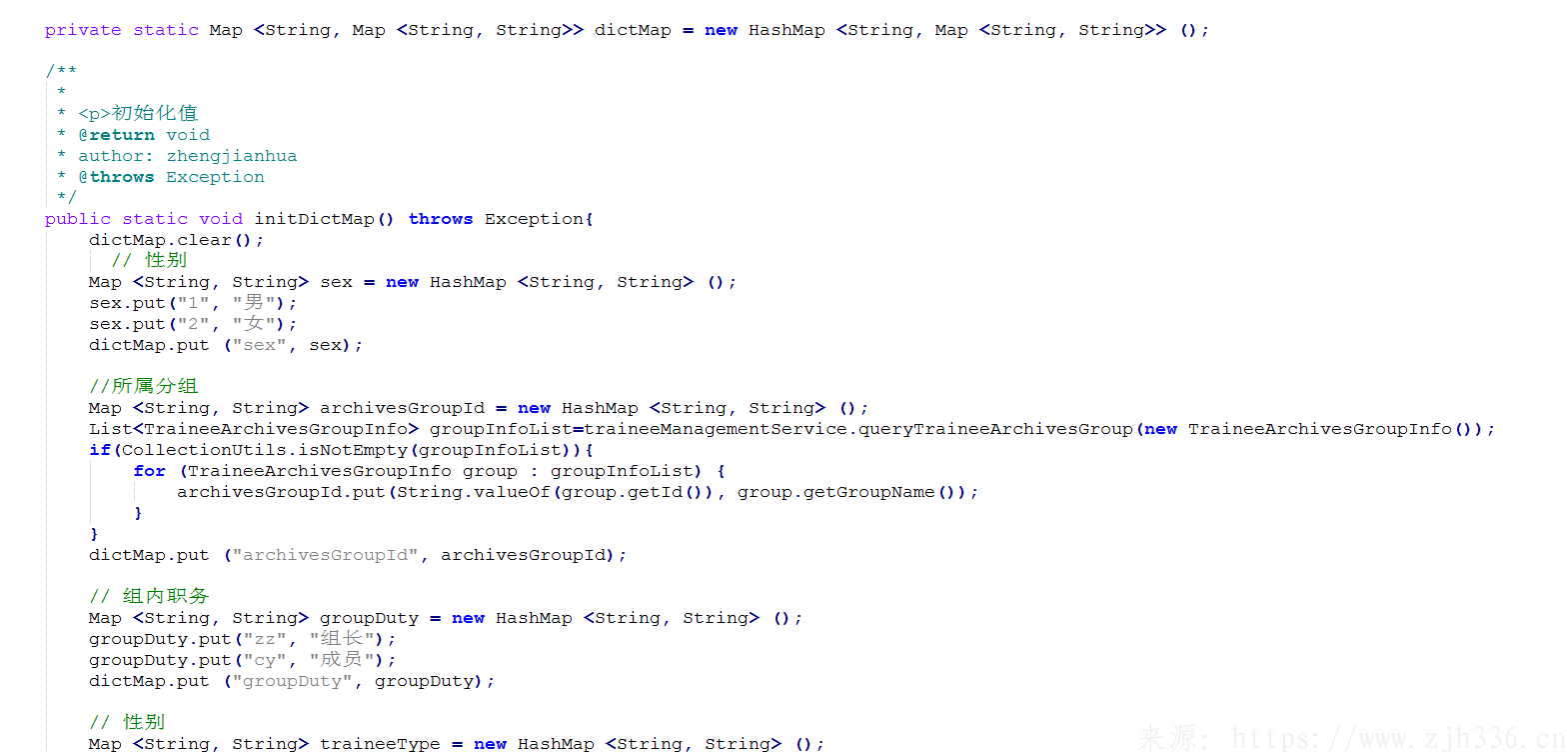
二、字典工具类
1、初始化值方法,工具类中定义了一个静态Map用于保存字典map的一个大Map。初始化方法中,将程序中可能涉及到的值域全部设置到Map中。Map的key值一定要与实际使用的注解的字典key值保持一致。
2、提供其他方法,获取字典map,根据value获取key,根据key获取value。

三、导出工具类(重点)
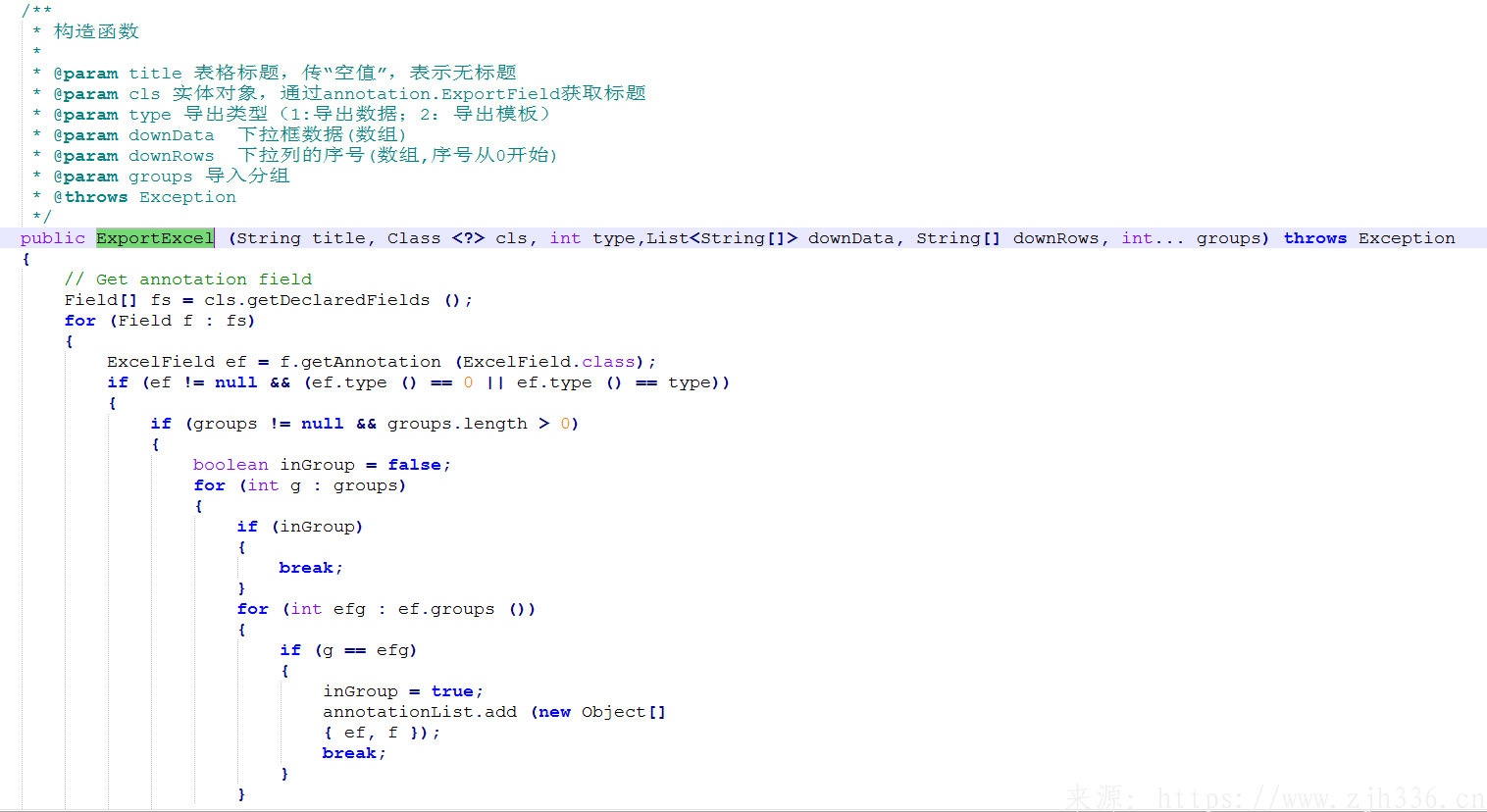
1、主构造函数。参数包含,导出文件标题,javaBean对象的类,导出类型,下拉数据值域,下拉数据对应的下标。下拉数据相关内容,可以从外部传入,也可以走默认下拉数据生成。逻辑主要是,先对javaBean对象类进行解析生成需要的字段信息。再根据字典工具类中的map生成下拉数据值域和下拉数据对应的下标。注意,此处要使用正常的话,javaBean注解的sort 必须是从1开始的,且连续。否则下拉数据下标会对应不准确。
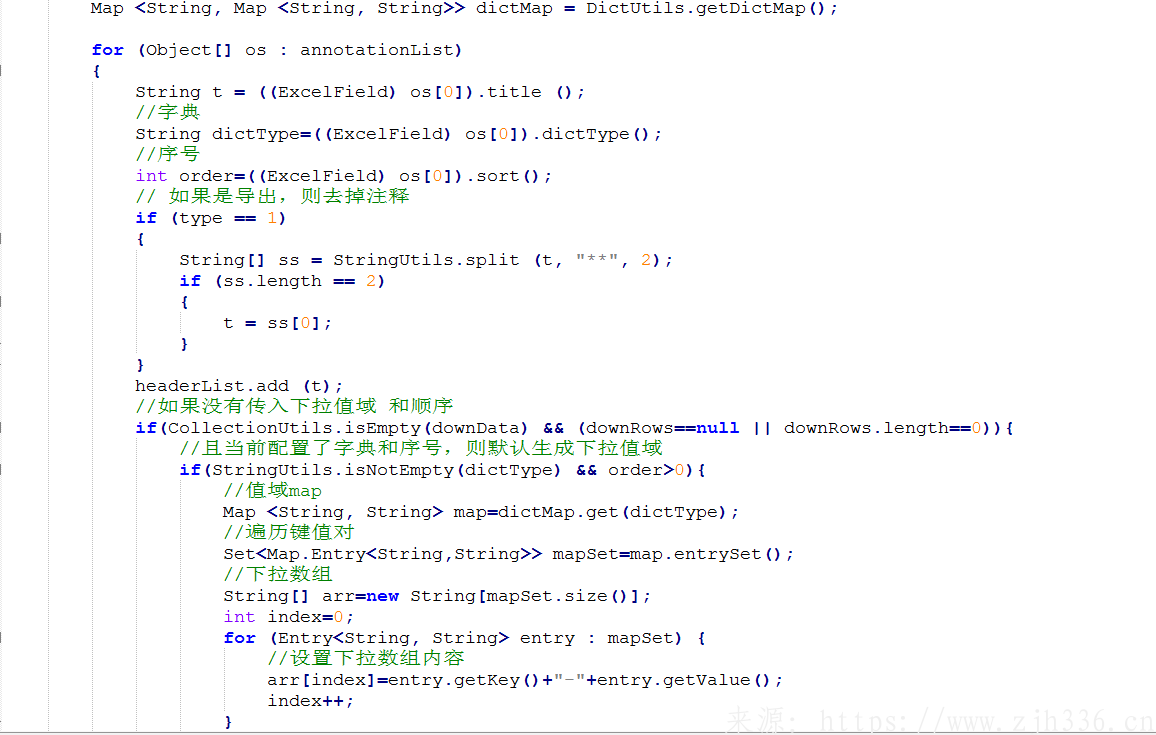
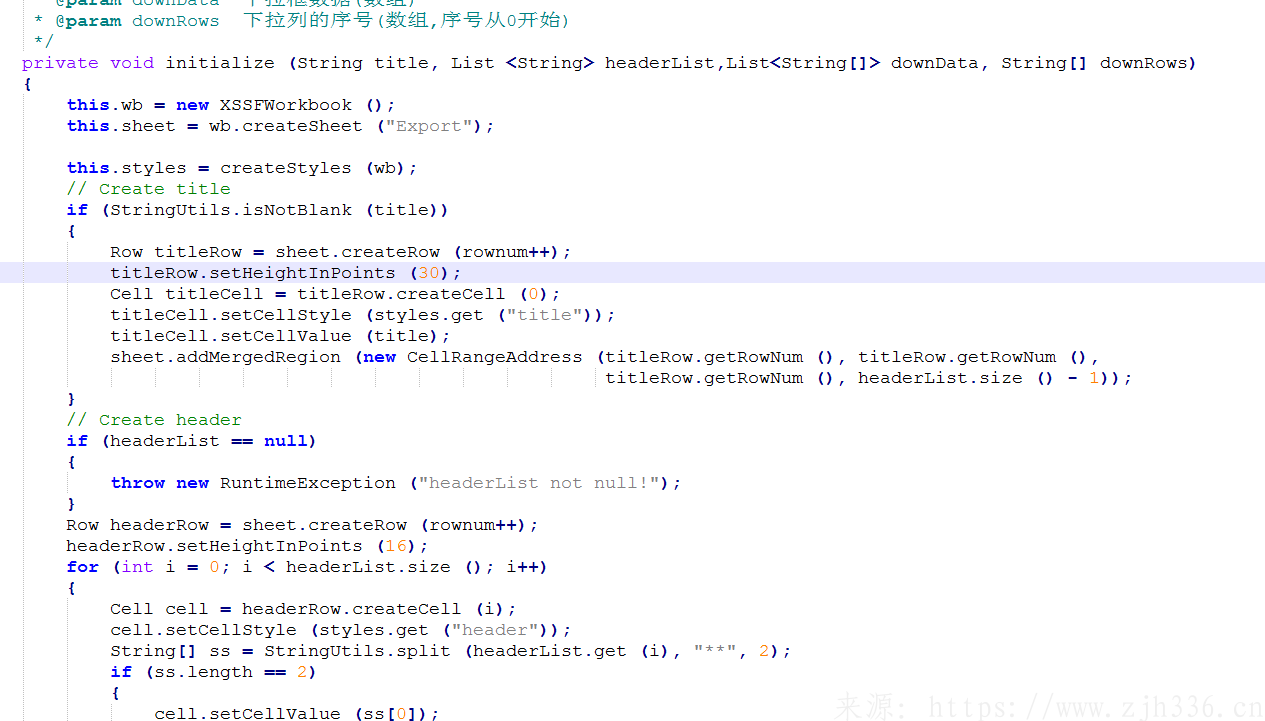
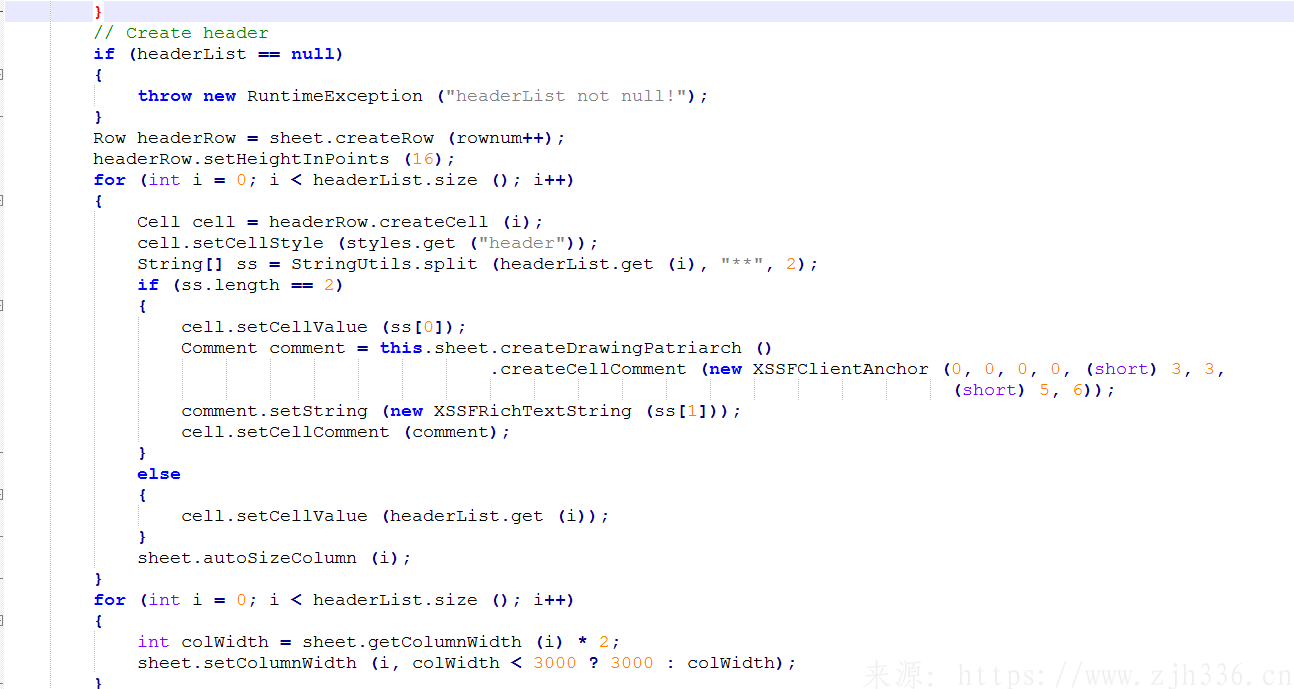
2、excel初始化函数。包括sheet页的生成,表头项的生成,以及下拉框数据的生成。下拉框数据的生成包含两种,一种是数据量少的,一种是数据量多的。数据量少的,是将下拉的数据缓存到类似内存的地方(猜测)。而数据量多的是直接新建sheet页用于存放数据,将下拉关系链接到指定列。为保证数据准确无误,直接使用第二种方式。

3、测试方法,测试工具类是否正确。
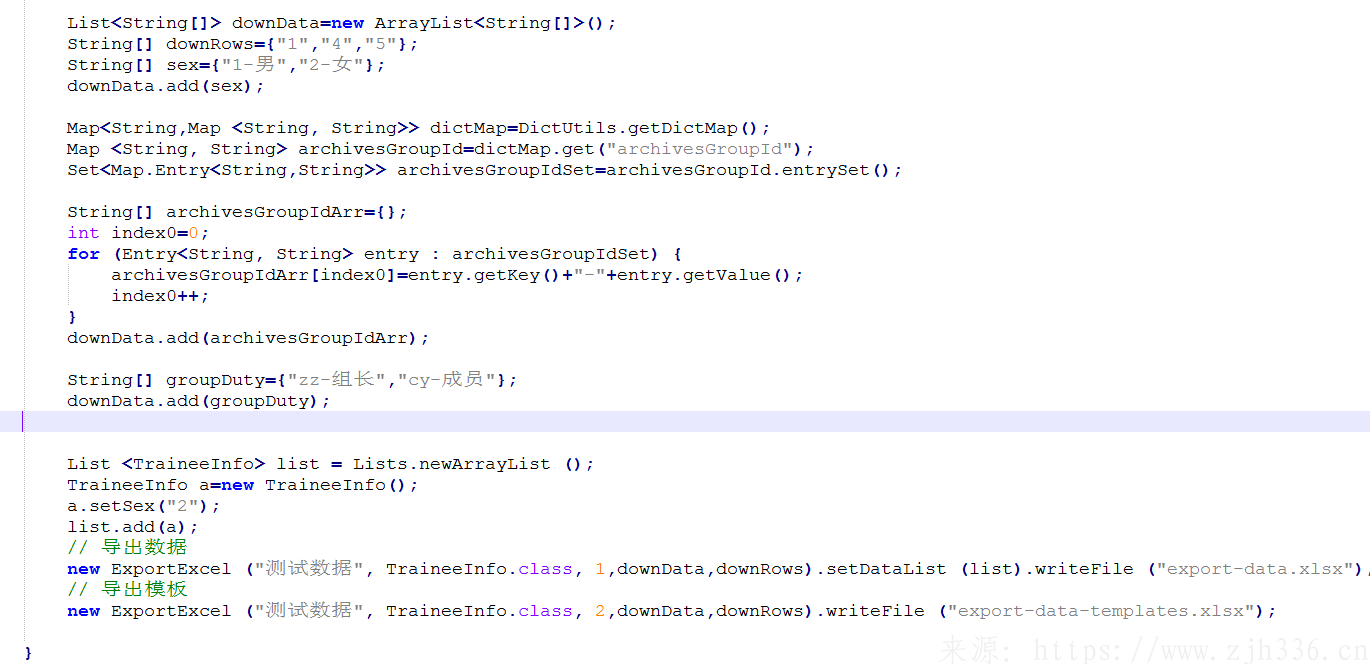
四、导入工具类(重点)
1、构造函数,根据文件名称等信息生成导入对象。
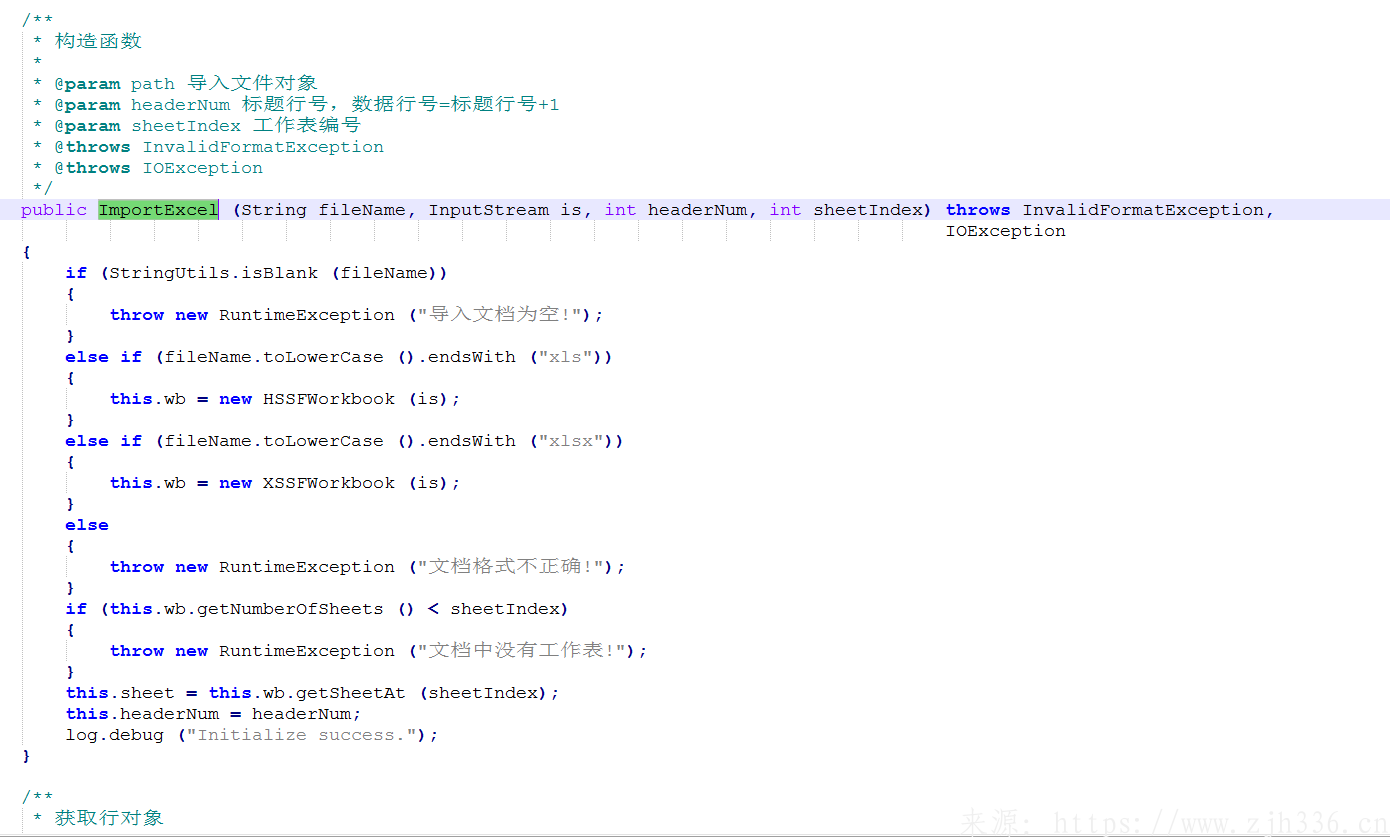
2、获取数据方法。根据javaBean的类,标签页,获取数据。此处做了特殊处理,带有字典标记项的,下拉框值域我是以键值对方式 key-value保存的,这里获取数据,只需要获取key值返回。
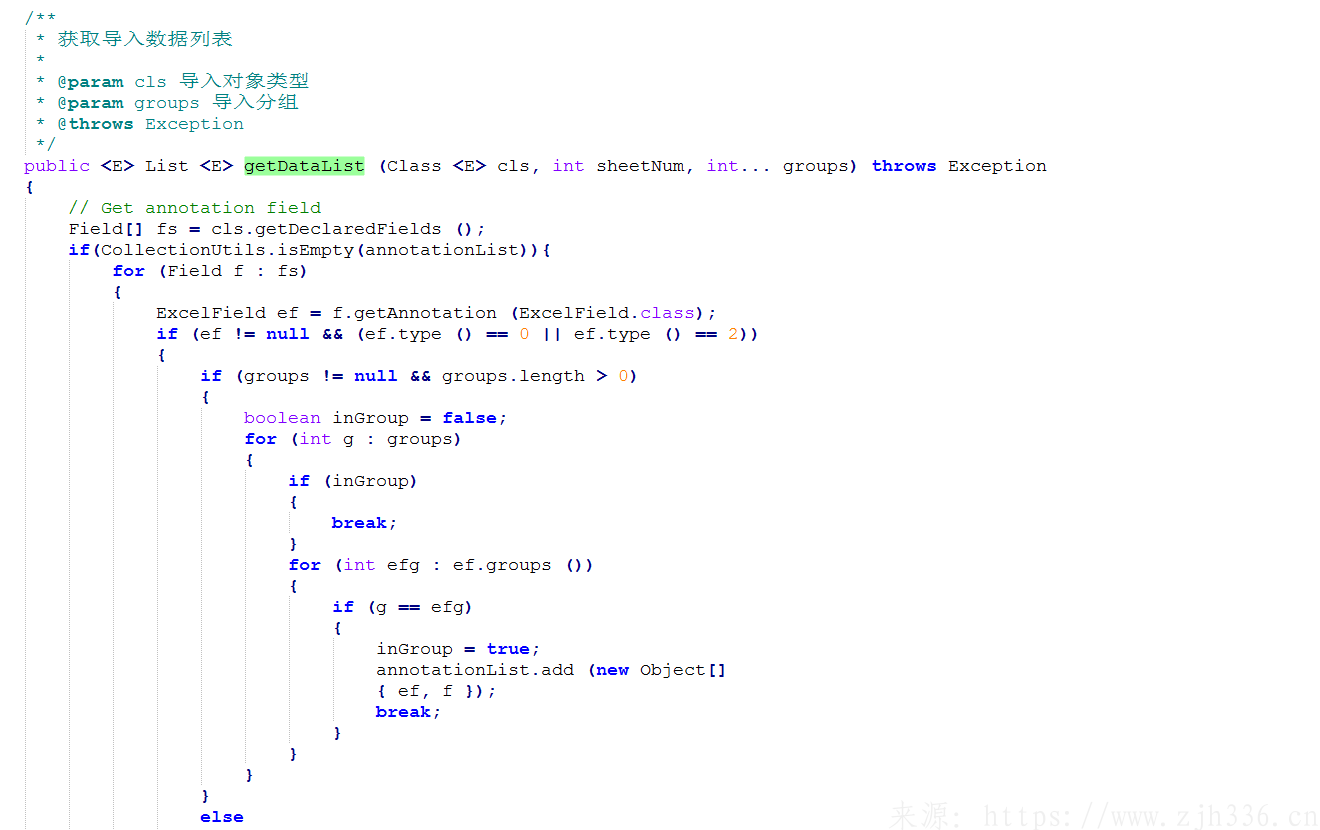
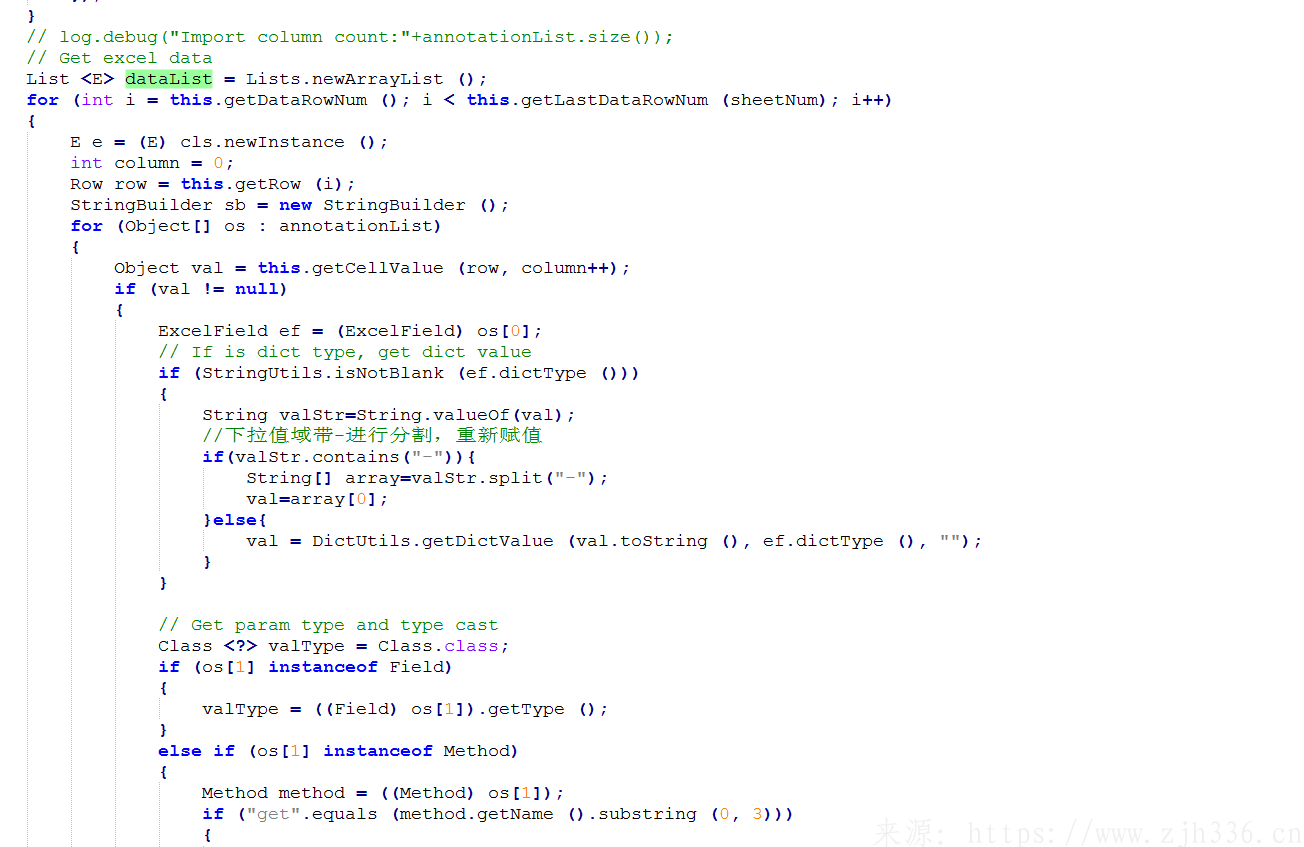
3、获取头部标题数据,用于验证导入数据格式正确。
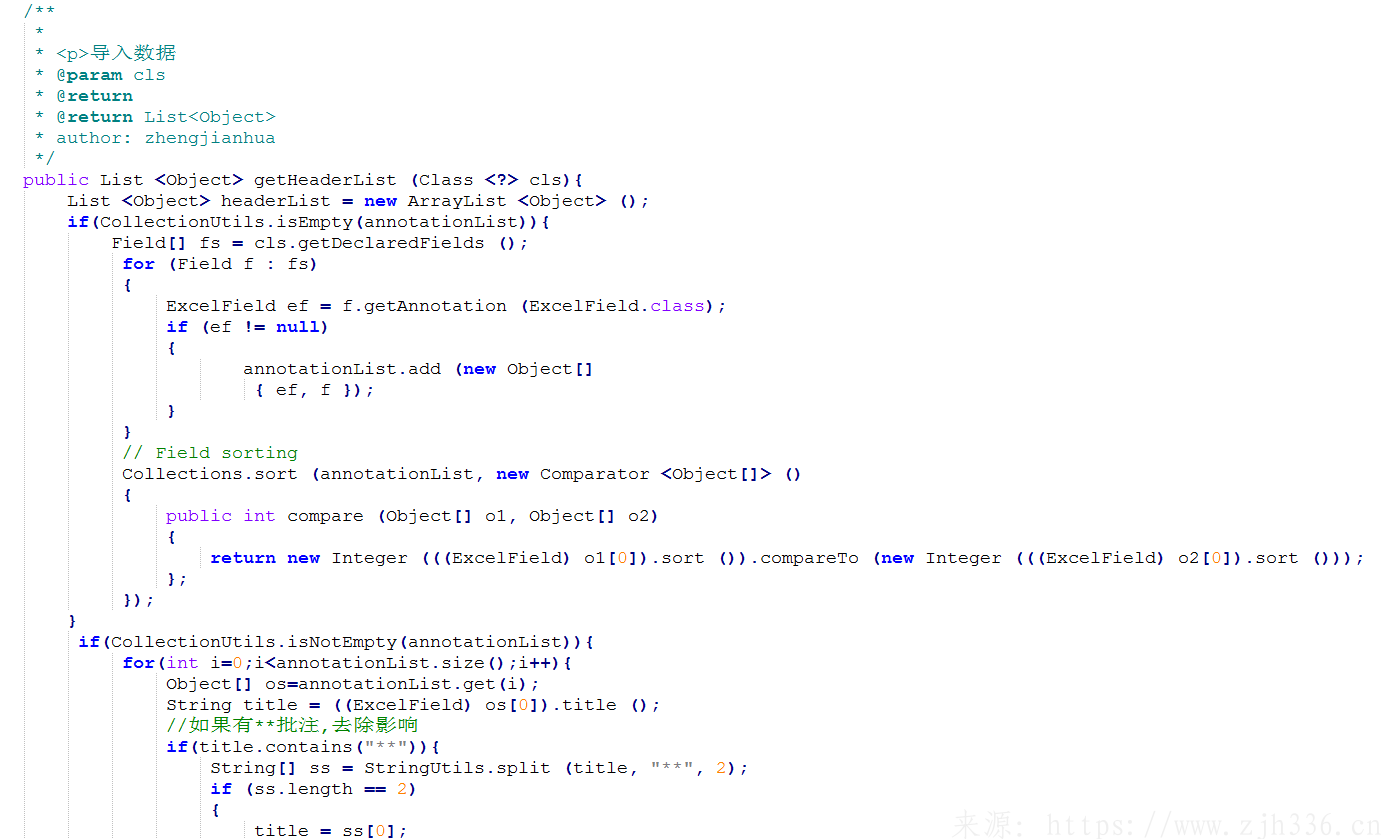
4、导入测试类

五、后端调用示例
1、javaBean配置示例。javaBean需要实现序列号接口,设置title,title中添加** 后面的内容显示在excel的批注中,sort设置的列序号

2、导出模板,以及示例数据 调用示例

3、导入数据 调用示例
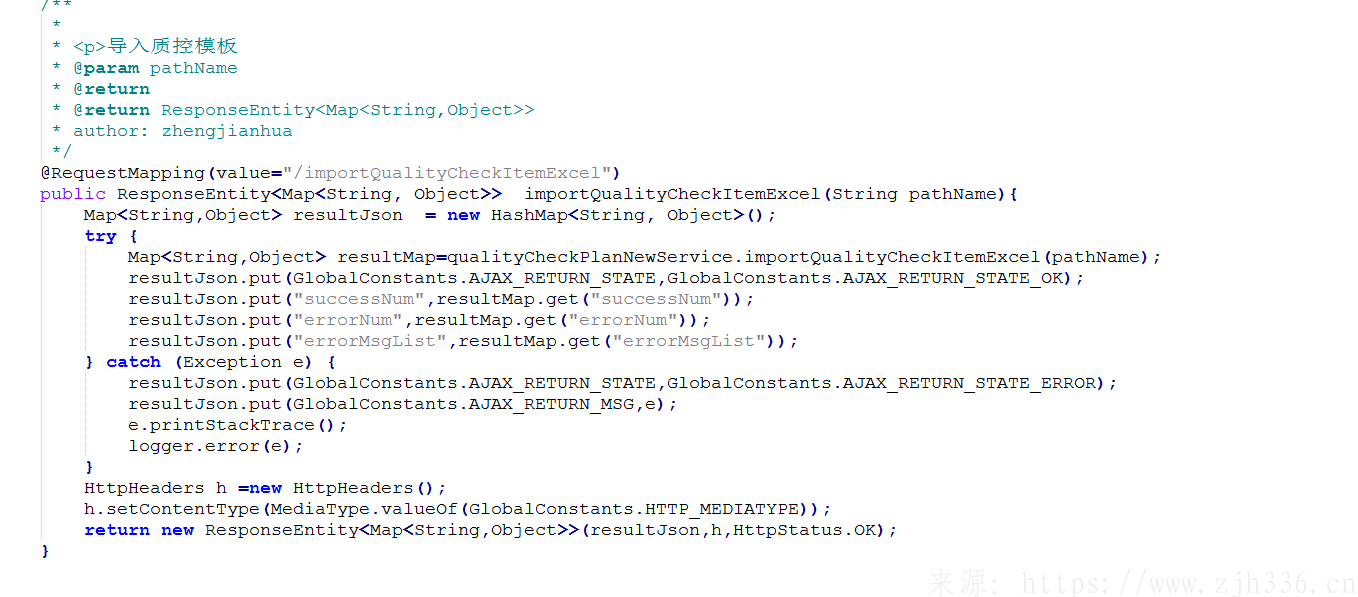
4、导入数据 服务示例。导入逻辑是根据实际业务逻辑进行编写,模板可以套用。支持多文件导入。循环文件进行导入,设置错误数量,导入日志信息集合。
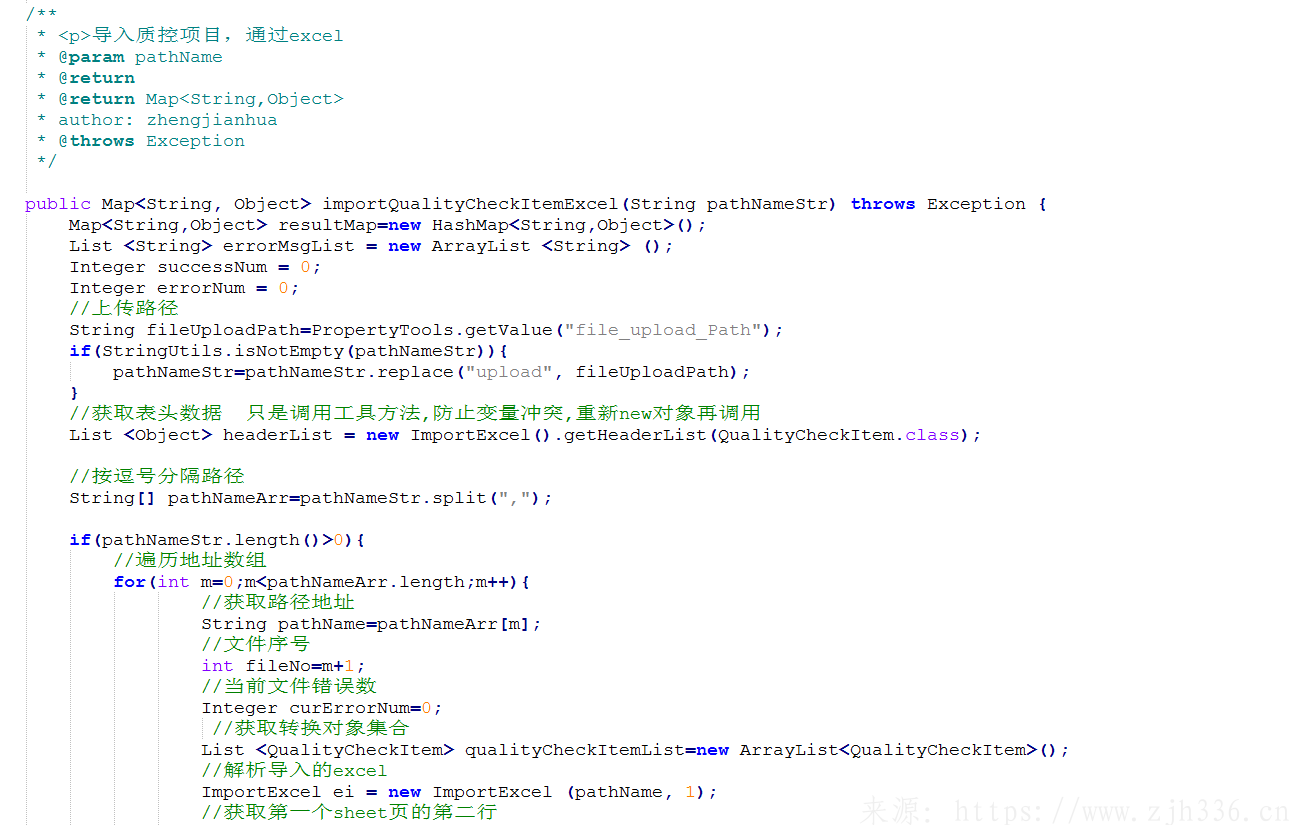
校验数据格式,判断必填项值是否为空。数据为空或者格式不正确的,跳出当次循环,继续其他文件解析导入。

具体导入逻辑中添加try catch ,已存在的数据直接提示信息,新数据走插入逻辑,并且出现错误仅记录错误信息,最终将数量和信息返回前端

六、前端调用示例
1、下载模板、下载示例、上传文件、导入文件。
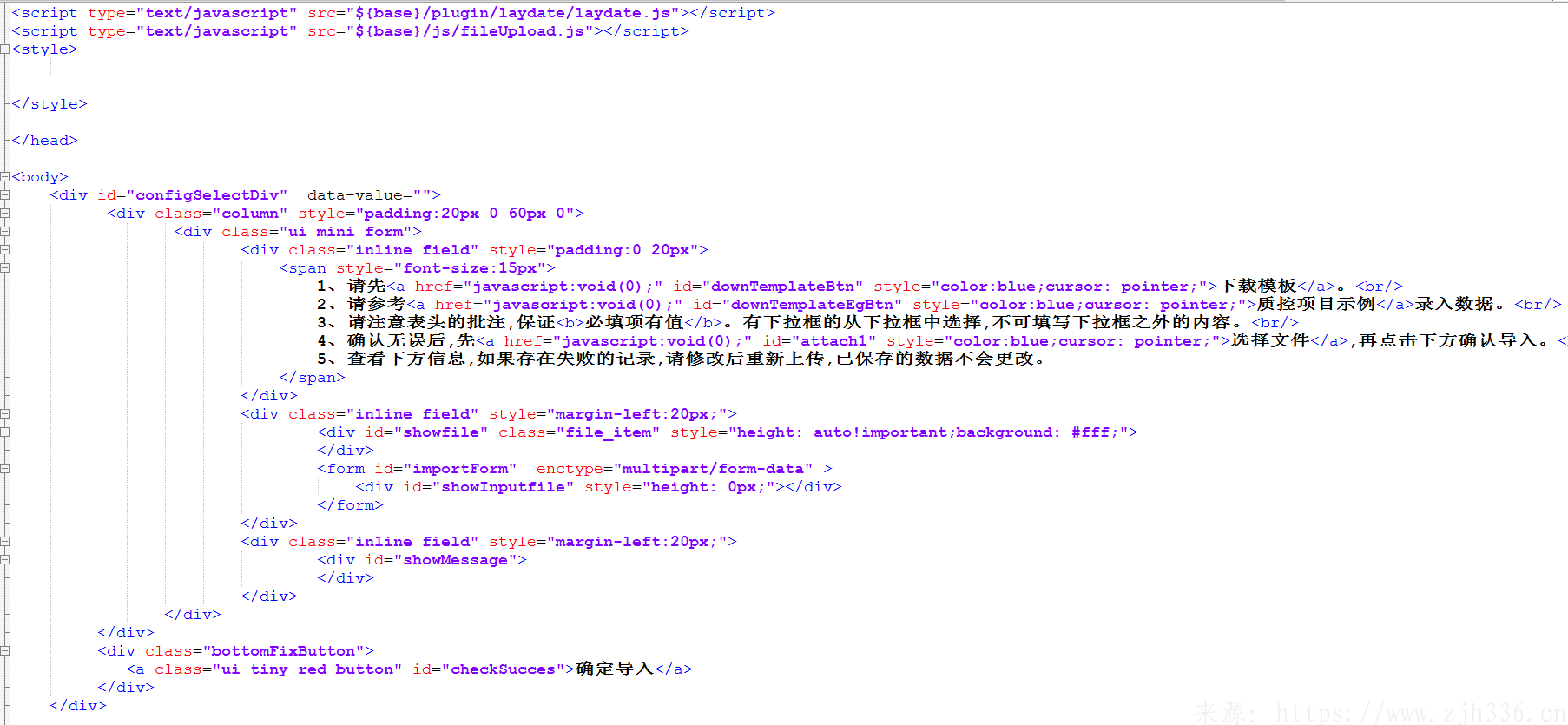


2、上传插件
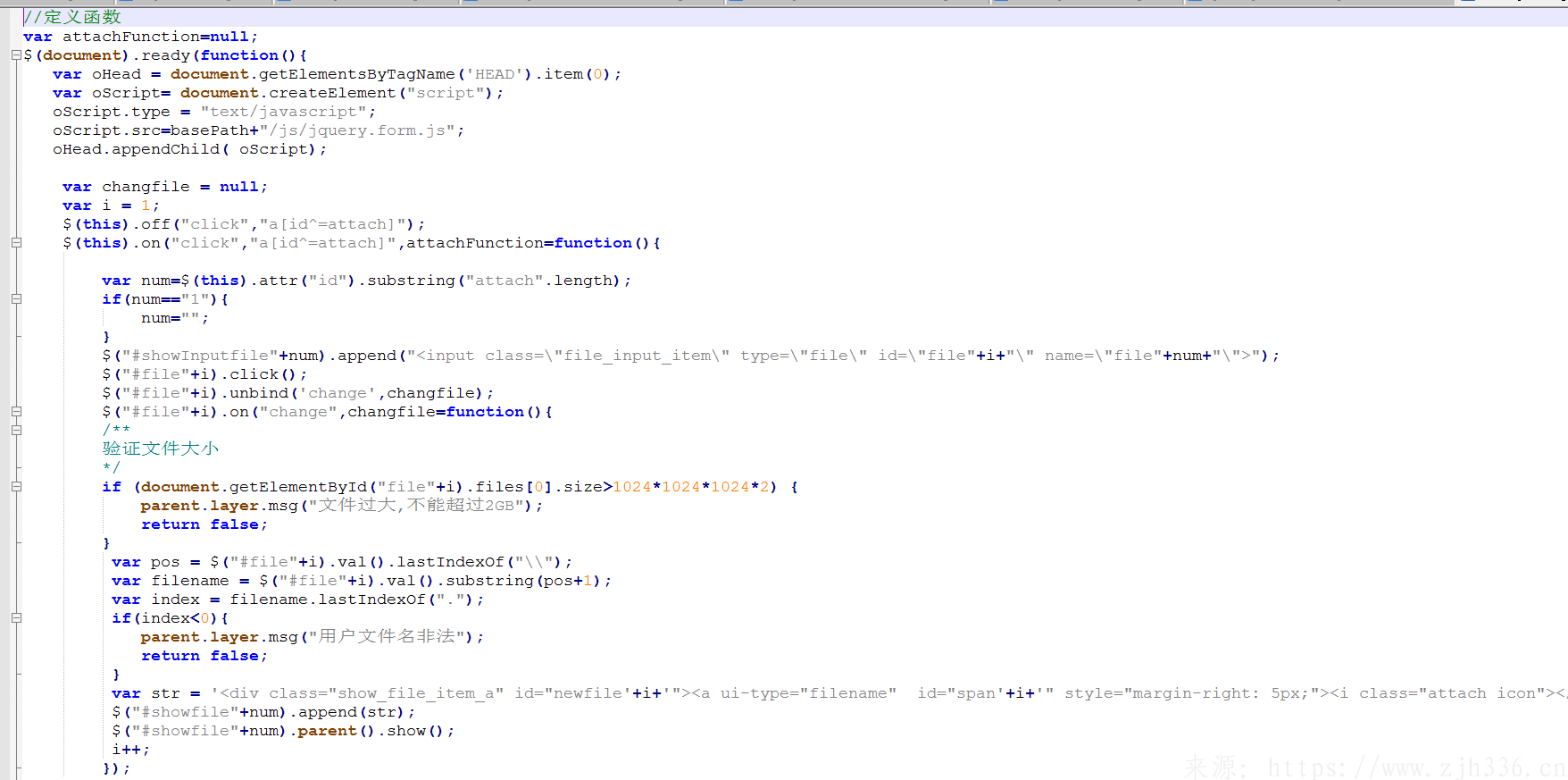
七、页面效果
1、导入界面
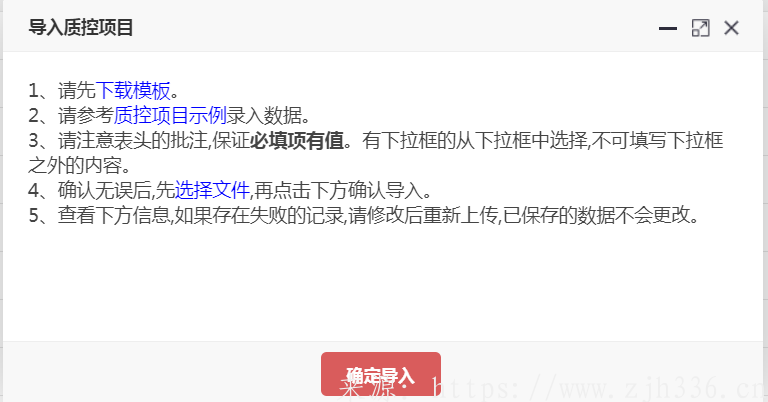
2、下载的模板
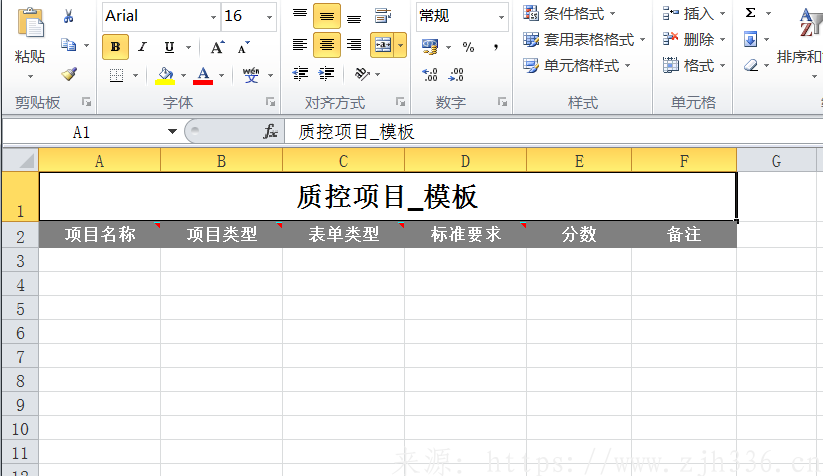
3、下载的示例
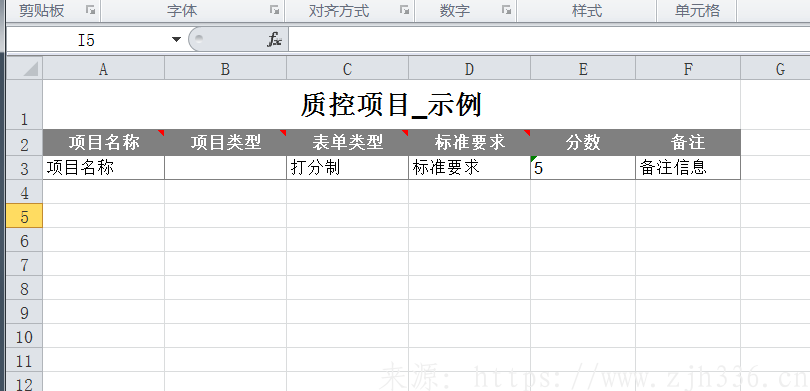
4、真实模板数据

5、多文件选择

6、导入完成界面

八、源码下载地址
评论回复获取分享密码




发表评论